
Table of Contents
Introduction
Do you believe that nearly 90% of the world’s data was created when the last two years? This demonstrates how important it is for AI to find hidden insights in data. The use of unsupervised learning is the ability of AI that enables machines to explore and analyze data on themselves.
In this post, we are going to look at the mysteries of unsupervised learning. It is transforming the future of artificial intelligence. We’ll look at its key theories, applications, and differences from supervised learning. Prepare to explore how robots can extract fresh insights from massive volumes of data.
Prepare for an amazing trip through unsupervised learning. We’ll talk about clustering techniques, dimensionality reduction, and more. By the conclusion, you’ll understand how this AI method is transforming industries and creating new opportunities for creativity.
Unveiling the Mystery: What is Unsupervised Learning?
Unsupervised learning represents a interesting aspect of machine learning. It enables algorithms to discover hidden patterns in data without any assistance. This is different from supervised learning, which uses labeled data to learn.
Unsupervised learning helps machines to figure out hidden patterns in data. This allows them to uncover new things that we may not have seen previously.
Explore the Field of Unsupervised Learning
Unsupervised learning algorithms are looking for similarities and patterns in data. They organize data in logical ways. This is ideal for complex data if we are unsure what we are looking for.
These algorithms can discover new insights through self-learning. Such knowledge may trigger fresh ideas and improved choices.
Contrasting Supervised and Unsupervised Approaches
Supervised learning is good for tasks like predicting outcomes. But unsupervised learning is better at finding patterns in data. This makes them work well together.
Supervised learning gives the rules, and unsupervised learning finds the hidden details. Together, they can solve many problems and find new things.
Knowing the difference between supervised and unsupervised learning helps us use machine learning better. We can solve more problems and find new insights.
| Supervised Learning | Unsupervised Learning |
| Requires labeled data | Works with unlabeled data |
| Focuses on predicting specific outcomes | Aims to discover hidden patterns and structures |
| Well-suited for classification and regression tasks | Excels in exploring complex, unstructured datasets |
| Provides guidance and structure | Allows for the discovery of novel insights |
Clustering Algorithms: Grouping the Ungrouped
Looking at clustering, we’ll examine k-means, hierarchical clustering, and DBSCAN techniques. All of them are techniques that will group similar data points together and form the backbone of unsupervised learning.
K-means algorithm groups data into k clusters. It codes each point to the nearest cluster, then updates its center. It is the algorithm that is really very simple but useful for a lot of tasks. It creates a hierarchy of clusters. It is suitable for analyzing data at different scales. It is relevant if the shape or size of clusters is unknown.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) It does any shape and size of clusters. It also detects outliers. DBSCAN is powerful for finding complex patterns in the data.
| Algorithm | Description | Strengths | Weaknesses |
| K-means | Partitions data into k distinct clusters | Simple, efficient, and scalable | Requires prior knowledge of the number of clusters (k) |
| Hierarchical Clustering | Builds a hierarchy of clusters | Flexible, can handle different cluster shapes and sizes | Computationally expensive for large datasets |
| DBSCAN | Density-based clustering, can identify clusters of arbitrary shape and size | Robust to outliers, can handle non-convex clusters | Requires careful selection of hyperparameters |
Exploring clustering algorithms helps us find hidden data insights. These tools are crucial for uncovering patterns in complex data. They are essential for unsupervised learning.
Dimensionality Reduction: Simplifying Complexity
An important technique applied in the unsupervised learning world of dimensionality reduction is used to understand better high-dimensional data. Dimensionality reduction enables us to reduce features in high-dimensional data, making complex data simpler and revealing hidden insights.
PCA: Principal Component Analysis
One of the most general techniques of reducing data space is known as Principal Component Analysis(PCA). The primary components of any data contain the most prominent variance and are used while projecting that data into some lower-dimensional space.
This is great for visualizing and analyzing complex data. It helps us spot patterns and relationships that were hard to see before.
t-SNE: A Novel Technique
Another important technique is t-SNE (t-Distributed Stochastic Neighbor Embedding). Unlike PCA, this technique emphasizes maintaining the local structure of the data. This makes it suitable for cluster finding and complex relationships visualization.
The t-SNE algorithm maps high-dimensional data into 2 or 3D with lovely resultant visualizations, and it is from these visuals that hidden patterns in the data are unearthed. PCA and t-SNE are essential tools in unsupervised learning. Both of these methods help us simplify data and open its secrets. We can better understand our data with these methods of dimensionality reduction. This opens up new ways for visualization and analysis.

Anomaly Detection: Outlier Detection
Anomaly detection is very important within unsupervised learning and has much significance in finding rare and unexpected events in our data. This method is applied to various areas, such as fraud stopping, keeping systems safe, and checking the quality of the products..
Unsupervised learning algorithms are great at finding these outliers. They use statistical methods and machine learning to spot patterns and oddities. This way, they can find data points that are way off from the usual, giving us important insights and warnings.
Cluster analysis is a basic technique in anomaly detection. It groups similar data points together. This helps us see which points don’t fit in, showing possible anomalies. Also, density-based methods look at how dense data points are. They mark areas with low density as possible outliers.
More complex statistical methods like Mahalanobis distance and one-class support vector machines help too. These methods create a model of what normal data looks like. Then, they find data points that don’t fit this model, marking them as anomalies.
Machine learning models like isolation forests and autoencoders take anomaly detection even further. These models learn the data’s patterns and spot big differences without needing labeled examples. This makes finding anomalies easier and more accurate.
By using unsupervised learning, companies can stay ahead of problems. They can find and fix anomalies early, preventing bigger issues. Anomaly detection changes the game in fraud prevention and quality control, among other areas.
Association Rules: Discovery of Hidden Patterns
Association rule learning is a big deal in the world of unsupervised learning. It helps discover patterns and relationships in data, which leads to insights that may shape business decisions and optimize operations.
Market Basket Analysis: A Practical Application
Association rule learning shines in market basket analysis. This method, often using the Apriori algorithm, looks at what customers buy together. It helps businesses improve their products, manage stock better, and offer a more tailored shopping experience.
The Apriori algorithm is key in this field. It scans big datasets, finds common items, and creates rules based on support and confidence. This helps businesses find product connections, leading to better sales and happier customers.
Market basket analysis gives businesses a lot of useful information. For instance, it might show that diaper buyers also like baby wipes. Or, power tool buyers often want accessories too. With this info, companies can place products wisely, run targeted ads, and manage their stock better.
But association rules aren’t just for retail. They’re useful in finance, healthcare, and more. As data mining grows, association rule learning will be vital for making smart, data-based choices.
Latent Variable Models: The Invisible Realities
Latent variable models play a big role in unsupervised learning. It helps reveal the underlying factors of the data we perceive. It mainly consists of factor analysis and principal component analysis. These models provide great insight into complex data.
Factor Analysis and Principal Component Analysis
Factor analysis finds the hidden factors that link observed variables. It looks at how variables relate to each other. This helps us understand the hidden forces at work in the data.
Principal component analysis (PCA) reduces data dimensions. It turns original variables into new, uncorrelated ones. The first component captures the most data variance. PCA is used in many fields, like image recognition, to find key features.
Both factor analysis and PCA are strong latent variable models. They reveal hidden data structures and patterns. This helps us make better decisions by understanding the data’s underlying processes and relationships.

Self-Organized Maps: Brain-Inspired Learning
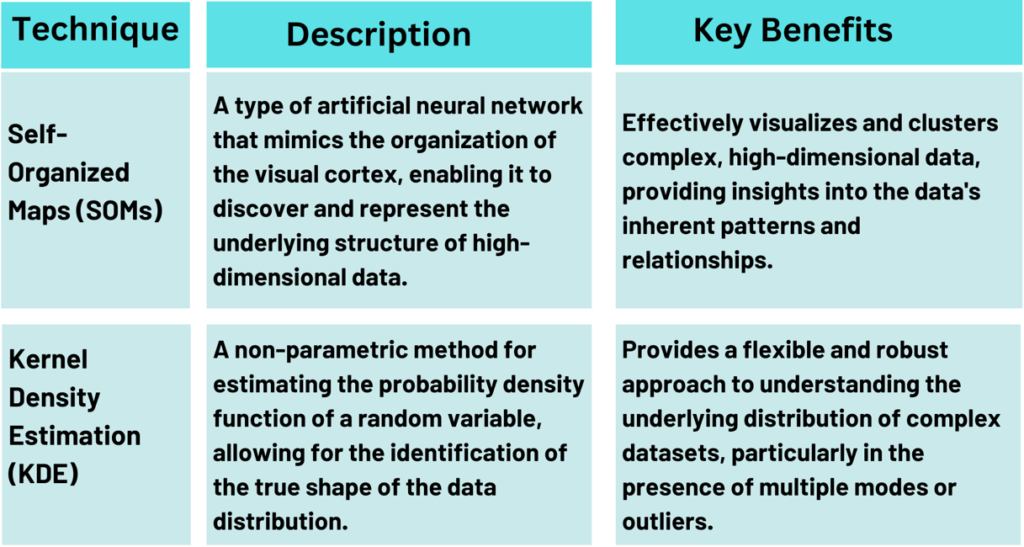
The SOM algorithm in the arena of unsupervised learning surpasses all others, as it resembles the functioning of neural networks within the human brain. It applies the method of competitive learning to discover unseen hidden patterns in complex data.
Unlike other methods, SOMs keep the spatial relationships in the data. They do this by creating a 2D grid of nodes. Each node represents a prototype vector.
The nodes compete to match the input data. The winning node and its neighbors are adjusted to better match the input. This process groups similar data points together, showing the data’s structure.
SOMs are great at handling high-dimensional data. They project high-dimensional data onto a lower-dimensional map. This makes complex data easier to visualize and explore.
They’re useful in fields like image processing and bioinformatics. These areas often have complex and high-dimensional data.
SOMs can learn without labeled data, making them perfect for unsupervised learning. Their ability to learn without labels and their easy-to-understand output has made them popular. They’re used in customer segmentation, market analysis, and anomaly detection.
As we explore unsupervised learning, SOMs show how brain-inspired techniques can reveal data secrets. They open doors to new discoveries and innovative solutions.
Density Estimation: revealing the data’s distribution
In the area of unsupervised learning, methods like self-organized maps (SOMs) and density estimates are essential. They assist us in discovering previously unknown insights in our data. These strategies replicate how our brains organize information, allowing us to better understand the patterns in our data.
Kernel density estimation (KDE)
Kernel density estimation is an effective method for determining the probability density function of a random variable. It differs from histograms in that it uses a flexible kernel function to smooth the data. This demonstrates the exact shape of the distribution.
This method is great for complex, multi-modal datasets. Traditional methods often can’t handle these. By using KDE, we can see the distribution of our data. We can spot clusters, outliers, and other key patterns.
This knowledge helps us in our analysis and decision-making. It leads to more informed and effective solutions.
By using these advanced techniques, we can explore the hidden structures and patterns in our data. This unlocks valuable insights that can guide better decision-making and lead to improved outcomes.
Natural Language Processing Unsupervised Learning
NLP is really a powerful tool for analyzing text data. It uses unsupervised learning to understand language in new ways. Techniques like topic modeling and word embeddings are changing the way we see language.
It’s such a potent tool in Natural language Processing because it enables the understanding of language in novel ways through unsupervised learning. Topic models and word embeddings, in particular, are transforming our view of language.
Topic modeling finds themes in text without manual help. It organizes content automatically. This helps researchers find hidden connections in text.
Word embeddings change how we represent language. They show how words relate to each other. This makes language processing more advanced, for tasks like text classification and machine translation.
Unsupervised learning also includes text clustering. It groups similar texts together. This is useful for organizing documents and finding new content.
Unsupervised learning has greatly changed NLP. It makes finding insights in text data more efficient. As NLP grows, we’ll see more uses of these algorithms, helping us understand language better.
| Technique | Description | Applications |
| Topic Modeling | Identifies underlying themes and patterns in text data | Content organization, text summarization, customer segmentation |
| Word Embeddings | Numerical representations that capture semantic relationships between words | Text classification, sentiment analysis, machine translation |
| Text Clustering | Groups similar documents or sentences based on their inherent similarities | Document organization, content discovery, customer segmentation |
Conclusion
In our investigation of unsupervised learning, we discovered AI’s extraordinary capacity to discover hidden jewels in large datasets. It combines clustering and dimensionality reduction to simplify complex data. This demonstrates how strong unsupervised learning is in AI.
Looking ahead, unsupervised learning will play an important part in AI’s future. It enables AI to discover patterns and learn on its own, without human intervention.
The future of AI is all about the expansion of unsupervised learning. The improvement in handling unstructured data by AI will result in significant improvements in language, vision, and robotics. As deep learning combines with Unsupervised learning, this will keep advancing the AI revolution. This will transform the way technology is used, and how data secrets can be discovered.